
")
We’ve all got used to the little numbered blue links in ChatGPT’s responses. They’re the citations that back up ChatGPT’s responses with external information.
But, although ChatGPT crawls dozens of pages to answer a single query, according to our research, it only ends up citing ~50% of them.
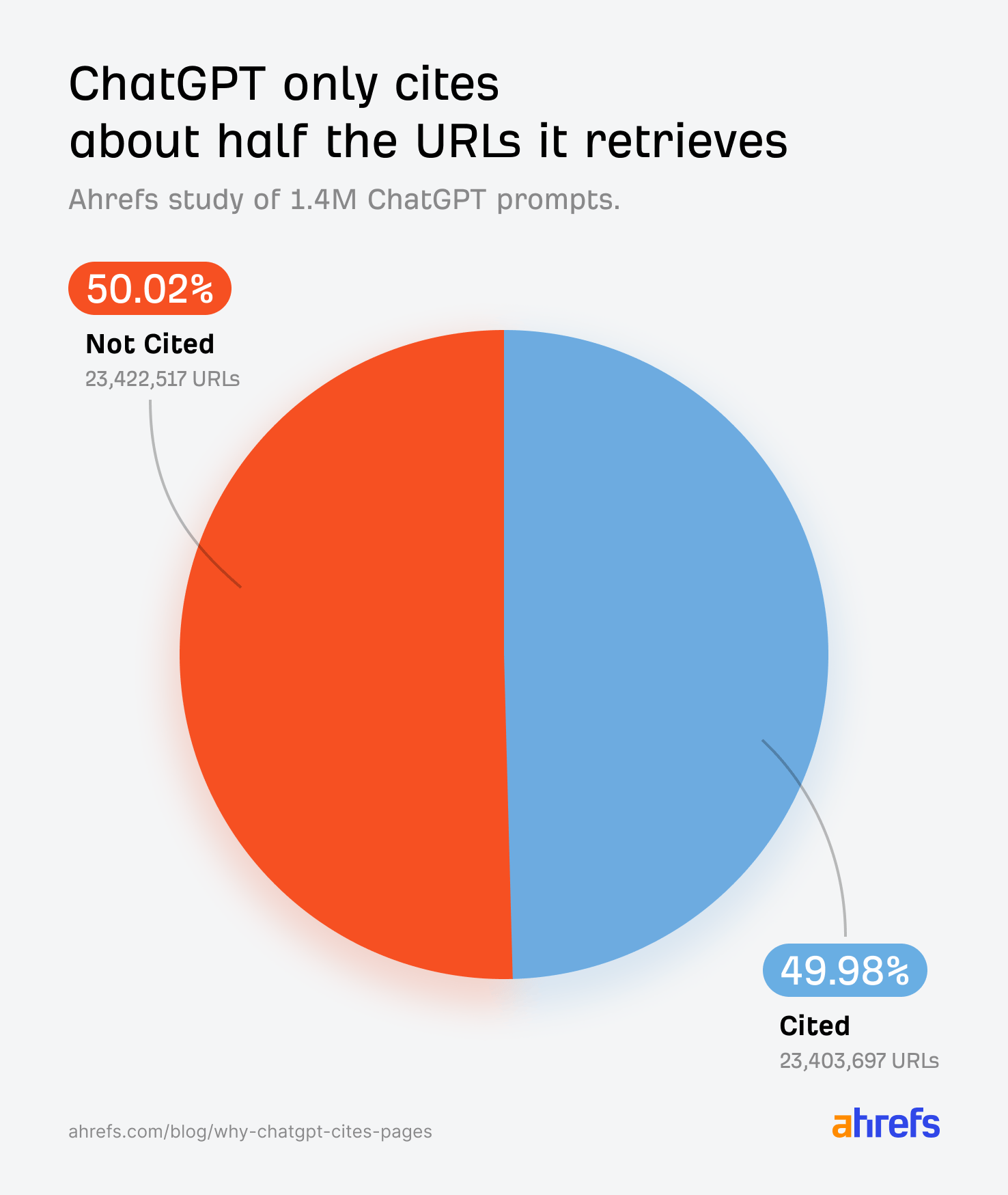
Why does one page get the credit while another, which the AI clearly retrieved, gets nothing?
According to studies by AI expert Dan Petrovic, when ChatGPT retrieves results, each one comes back with the page title, a brief snippet or summary, the URL, and an ID number.

ChatGPT uses this data to decide which pages are worth opening and eventually citing in its response.
That means there’s a gatekeeping layer before ChatGPT opens and reads any of your actual page content. The title, snippet, and URL are doing the heavy lifting in that initial decision.
So we wanted to know: what actually influences that decision? Does higher semantic similarity between a page’s retrieval data and the user query increase citation likelihood? Which fields matter most? Do human-readable URLs outperform opaque ones?
To find out, we analyzed 1.4 million ChatGPT 5.2 prompts from February 2025 (desktop) with the help of Ahrefs data scientist Xibeijia Guan.
But before we get into the findings, you need to understand how ChatGPT actually gathers its sources—because not all URLs enter the system the same way.
When ChatGPT retrieves results, it categorizes sources using an internal field called ref_type—essentially a label for the retrieval channel the URL came through.
We discovered five categories: search, news, reddit, youtube, and academia.
The citation rates between them are wildly uneven:
| ref_type | Citation % | Total data points |
|---|---|---|
| search | 88.46% | 25,563,589 |
| news | 12.01% | 3,940,537 |
| 1.93% | 16,182,976 | |
| youtube | 0.51% | 953,693 |
| academia | 0.40% | 185,337 |
The general “search” index dominates—both in volume and citation rate—and 88% of the URLs that end up being cited by ChatGPT are taken directly from search.
If you want to be cited by ChatGPT, you need to be in that search selection pool—which means your content needs to rank.
This isn’t new information. By now, most people are already aware that ranking plays a part, but it’s nice to have some more data to back it up.
Specialized verticals like YouTube (e.g. youtube.com) and Academia (e.g. arXiv.org), on the other hand, are pulled in at scale but barely ever get surfaced as actual citations.
Sidenote.
The “search” ref_type does include Reddit and YouTube results too—any Reddit or YouTube page that comes back through a standard web search will show up there.
The separate “Reddit” and “YouTube” ref_types likely represent additional results—i.e. those pulled in via dedicated API integrations—on top of whatever the web search already returned.
That’s why the volume on those channels is so high; ChatGPT is supplementing its search results with a separate feed of Reddit and YouTube content.
This matters a lot for interpreting the rest of the analysis.
On average, ChatGPT pulls ~16.57 cited URLs and ~16.58 non-cited URLs per prompt.
But because Reddit makes up 67.8% of the non-cited pool, any aggregate comparison of “cited vs. non-cited” is really comparing search results to Reddit API output. Not apples to apples.
So throughout this research, we’ve isolated the analysis by ref_type wherever possible to avoid that distortion.
This is probably the most striking finding in the dataset.
Reddit has its own dedicated ref_type in ChatGPT’s retrieval system, with over 16 million data points in our dataset.
Yet it’s cited at a rate of just 1.93%.
Meanwhile, 67.8% of all non-cited URLs come from Reddit.
In other words: ChatGPT is using Reddit extensively to understand topics, gauge consensus, and build context—but it almost never gives Reddit the credit.
It learns from the crowd, then cites another institution.
As we’ve briefly covered, when ChatGPT retrieves search results, each one comes back with a set of fields including a title, URL, and sometimes a snippet—a short extract of page content stored in ChatGPT’s retrieval data.
We expected that having more of these fields populated would correlate with higher citation rates.
At first glance, the aggregate data seemed to tell a different story: non-cited pages actually have more populated fields in ChatGPT’s retrieval data than cited ones.
Non-cited URLs had snippets 14.81% of the time versus 4.36% for cited URLs, and were far more likely to carry a publication date (92.72% vs. 35.98%).
We almost ran with that as a finding, but I’m glad we didn’t.
When we dug into it, the discrepancy turned out to be almost entirely a compositional artifact—driven by Reddit and the mechanics of ChatGPT’s retrieval pipeline.
Because the non-cited pool is overwhelmingly Reddit (67.8%), and Reddit content pulled via API naturally carries pub_date metadata, the 92.72% figure is a Reddit artifact—not a signal about how ChatGPT evaluates web pages in general.
The snippet gap is explained differently. According to David McSweeney’s research on ChatGPT’s retrieval process, the model actually abandons the snippet field (the short content extract)once it’s decided to cite a URL—and opens the full page instead.
So, it’s not a matter of ChatGPT preferring pages with no snippets. The low snippet percentage for cited pages is likely a byproduct of how the pipeline works.
When we isolated the data to just the “search” ref_type—stripping out Reddit, news, YouTube, and the rest—the picture became a lot clearer:
| Search ref_type | Has snippet | Has pub_date | Total URLs |
|---|---|---|---|
| Cited | 2.52% | 33.79% | 22,612,529 |
| Not cited | 0.09% | 49.00% | 2,951,060 |
Snippet data is basically non-existent for both groups within the search vertical—it’s not a usable signal. And the publication date percentages are closer, but non-cited search pages are still slightly more likely to carry a pub_date (49%) than cited ones (33.79%).
The differences we initially saw between cited and non-cited URLs seem to have been distorted by the data composition and retrieval mechanics. Any signal—if there is one—is buried under the noise. The honest takeaway: we can’t draw strong conclusions about whether the snippet or publication date fields play a meaningful role in citation from this data.
It’s worth flagging that this problem likely applies to other citation studies too. Any research comparing “cited vs. non-cited” URLs without accounting for where those URLs came from risks mistaking quirks of the data for real patterns.
Find your own citation gaps in Brand Radar
The data in this study tells you what ChatGPT values. Brand Radar tells you where you’re falling short.
Open Brand Radar, set up your brand and competitors, and head straight to the Cited Pages report.
Then, filter for responses where competitors are cited and you aren’t.
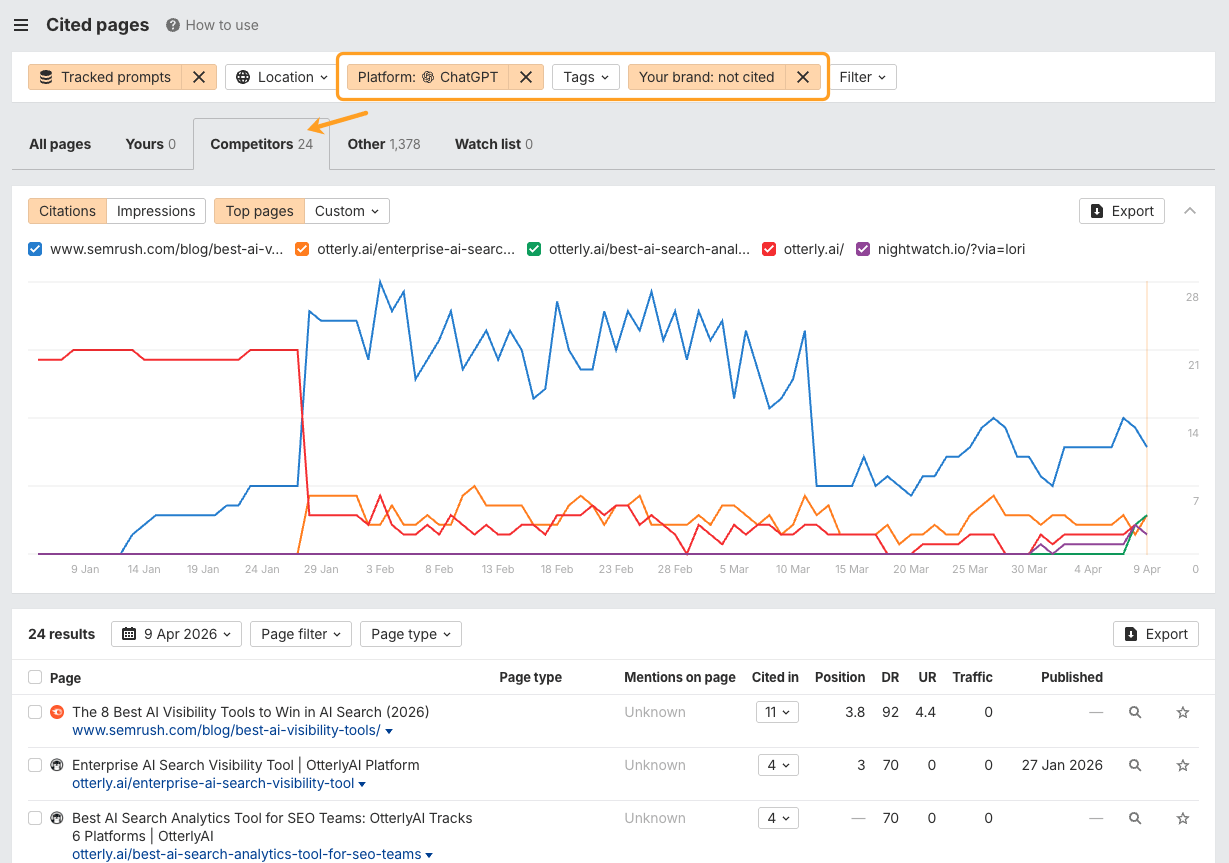
That gap analysis gives you a concrete list of content to create, refresh, or restructure.
To figure out what’s “citable,” ChatGPT estimates relevance, in a process sometimes described as “semantic scoring”, to judge whether an article and a query are related.
Since ChatGPT is a closed-source model, we don’t have visibility into exactly how it determines relevance internally.
So, in this study, we use cosine similarity computed from embeddings generated by open-source models, to quantify and approximate how ChatGPT may work.
ChatGPT matches URLs against its own “fanout queries”—the sub-questions it generates internally (from a user’s seed prompt) to hunt for specific facts.
The data confirms that title relevance to fanout queries is an important factor in citation:
- Prompt vs. cited URL title: 0.602
- Prompt vs. non-cited URL title: 0.484
- Fanout query vs. cited URL title (max match*): 0.656
Sidenote.
For each of these fanout queries, we compute its cosine similarity with the article title. The “max match” score is the highest similarity among them—for example, if scores are 0.45, 0.71, and 0.38, the max match is 0.71. This captures the best-aligned sub-question rather than averaging across all interpretations, which would dilute the signal.
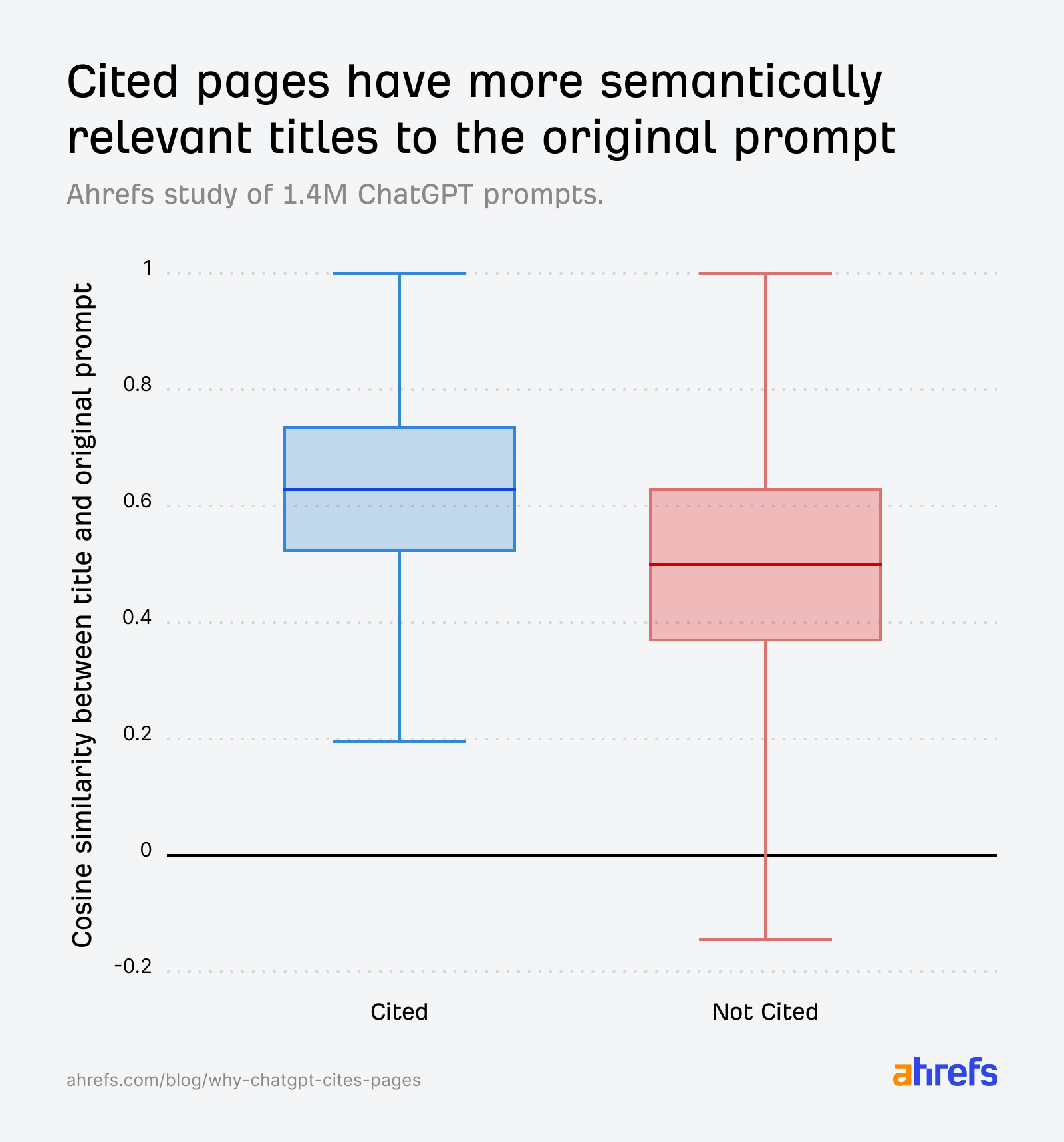
The box plots tell the story clearly. Across all ref_types, cited URLs have consistently higher similarity between their title and the original prompt:
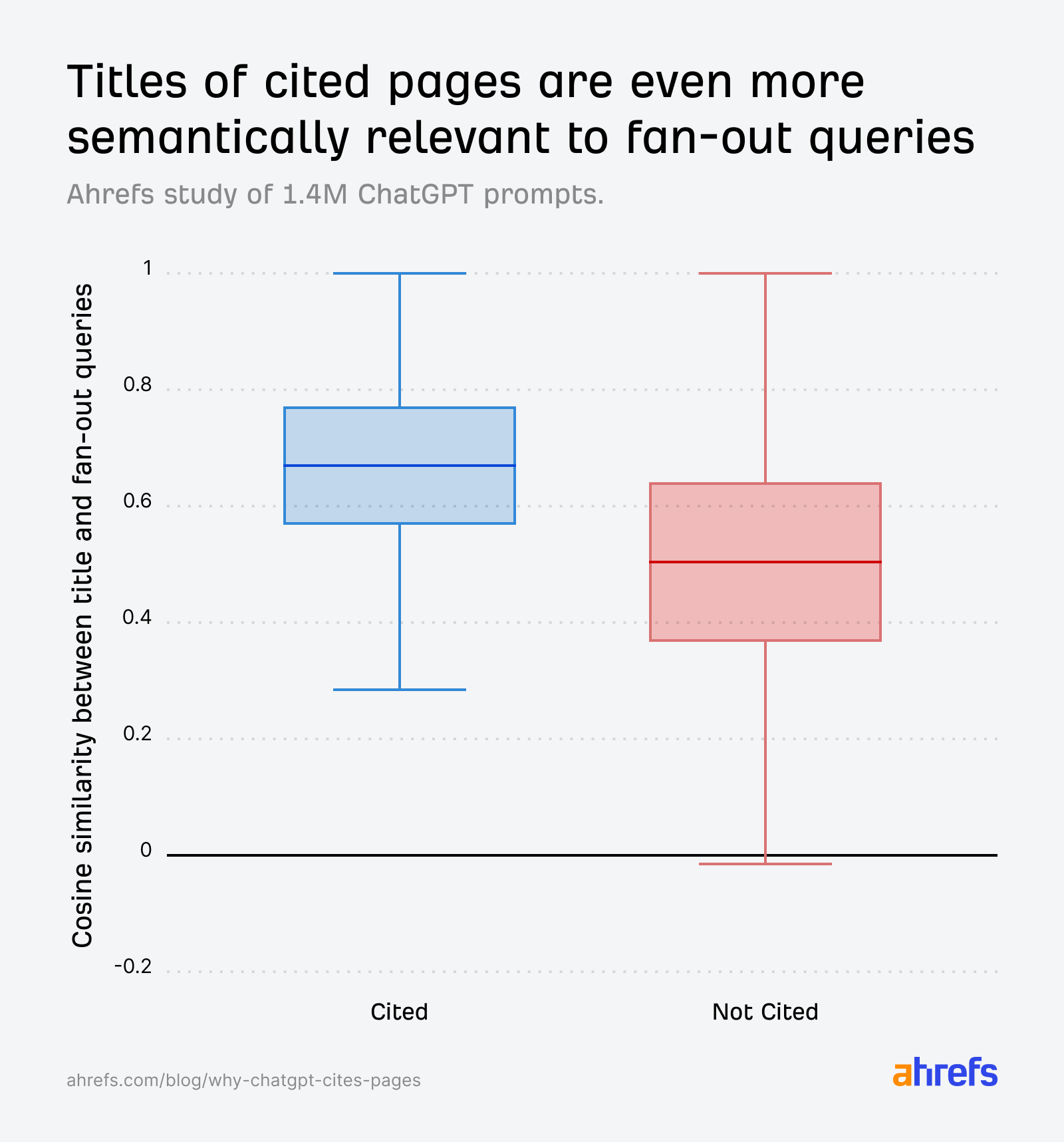
The gap widens further when we compare against fanout queries instead of the original prompt—reinforcing that creating content relevant to ChatGPT’s internal sub-questions are what really drive selection:
When we isolate the search ref_type specifically, the pattern gets even sharper. Cited pages are clearly more relevant, and the non-cited distribution drops significantly:
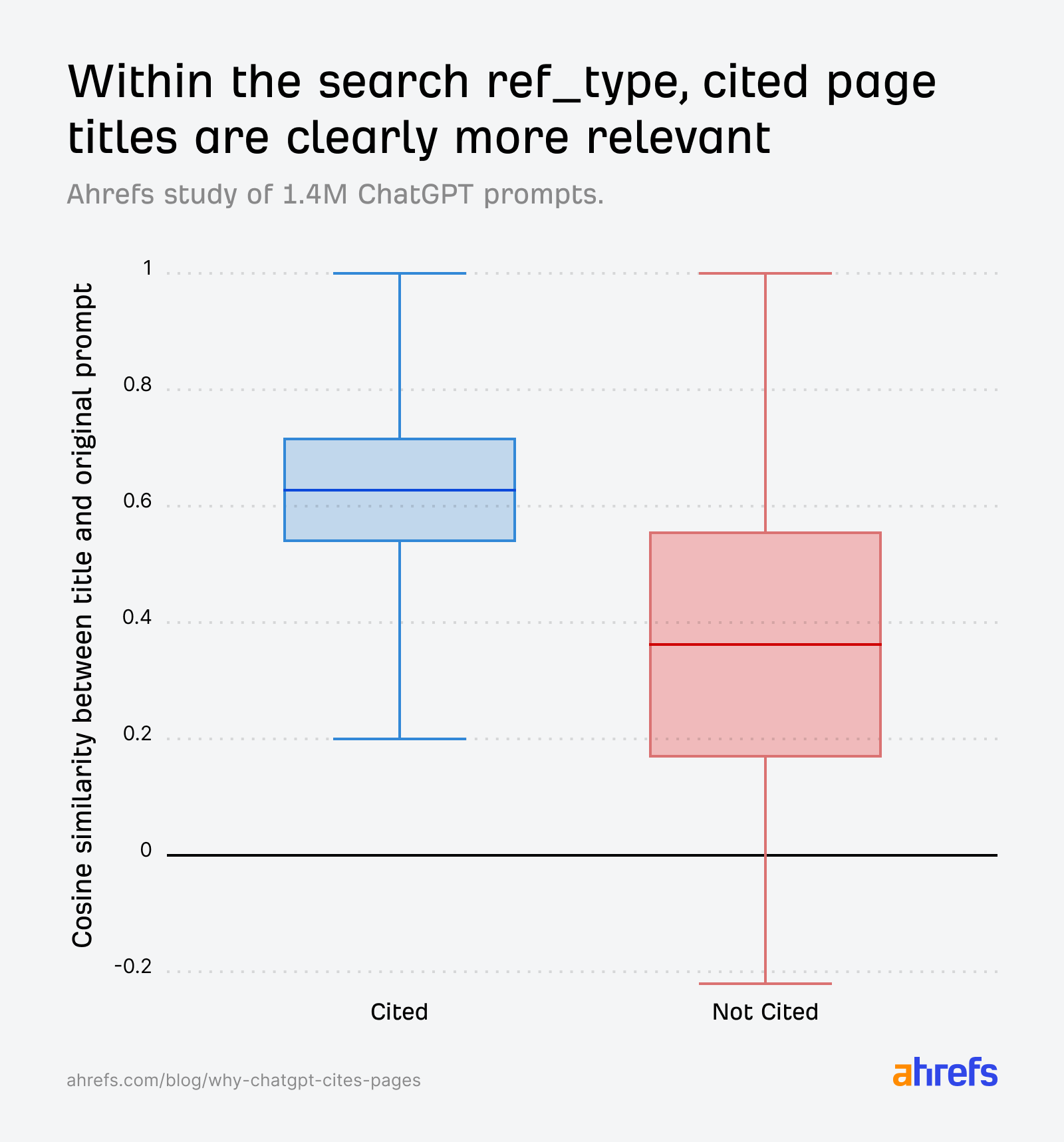
We also found that search results with natural language URL slugs had an 89.78% citation rate, compared to 81.11% for those without.
Ultimately, if your URL and title don’t semantically align with the AI’s internal fanout queries, you’re less likely to get cited.
Optimize for fan-out queries using Brand Radar
You can study fanout queries directly inside Brand Radar. Head to the AI Responses report, pick any prompt, and you’ll see the fanout queries ChatGPT generated alongside the cited URLs.
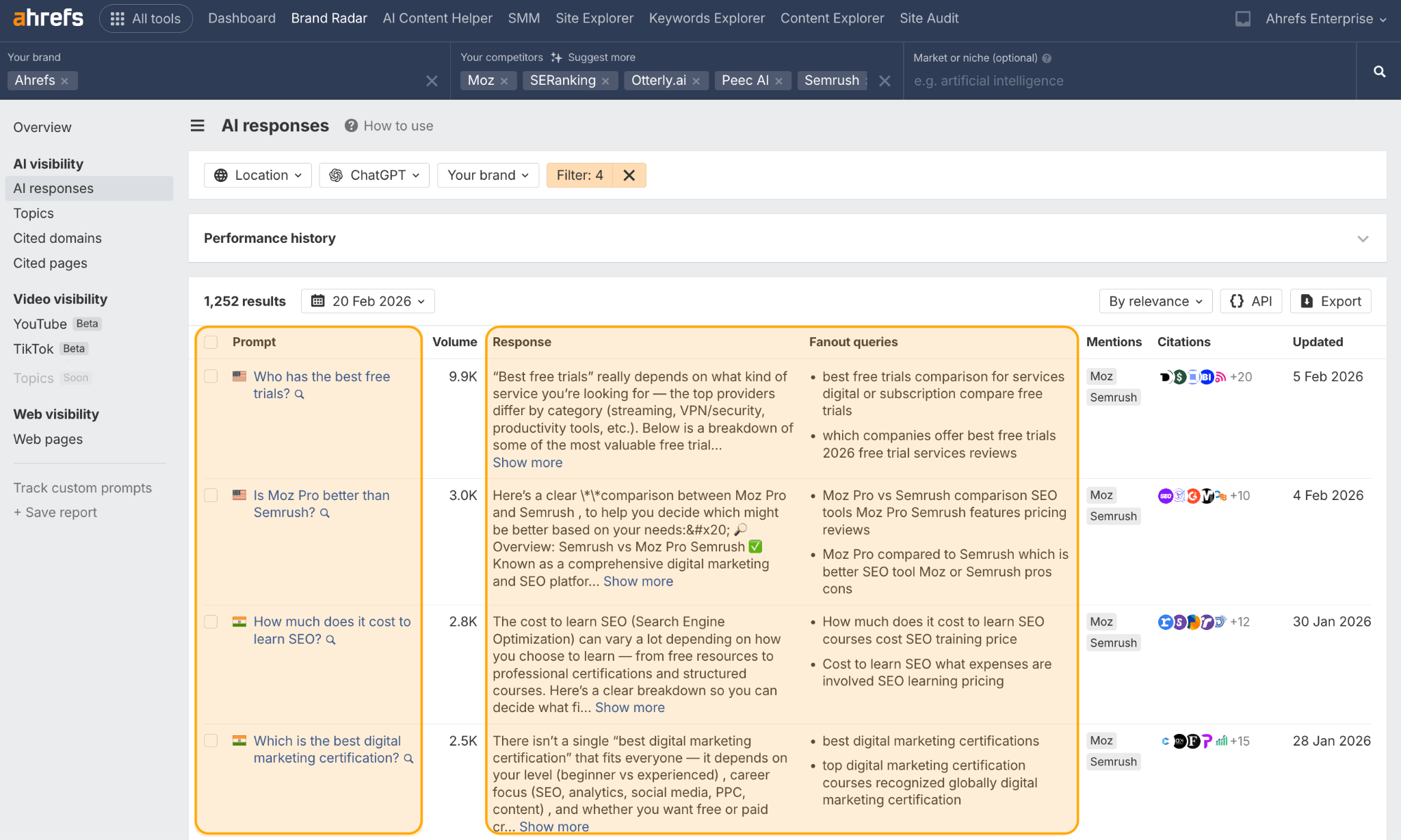
This is the actual set of sub-questions your content needs to answer.
From there, use the AI Content Helper to check how well your page covers the topics those fanout queries address. It measures the cosine similarity between your content and the topics the SERP or AI response is trying to cover—and gives you a colored highlight as you write, showing which gaps remain.

If a competitor’s page is getting cited for a query where yours isn’t, this is one of the fastest ways to diagnose why.
It’s common knowledge that fresher content gets cited more by AI—and, in fact, our own study of 17 million citations supports that. We found that ChatGPT cited URLs that were 458 days newer than Google’s organic results—the strongest freshness preference of any platform we tested.
This new data doesn’t contradict that narrative, but it does add an extra layer of nuance.
For instance, when we look at the search index, cited pages span a wide range of ages—the median is around 500 days (~1.3 years old), with some cited pages over 2,700 days old (~7.4 years old).
The median age is actually far lower than our initial freshness study linked above (958 days back in July vs 500 days in this dataset), suggesting that ChatGPT is skewing even younger in its citation preferences.
That said, we also found that non-cited pages are overwhelmingly very young.
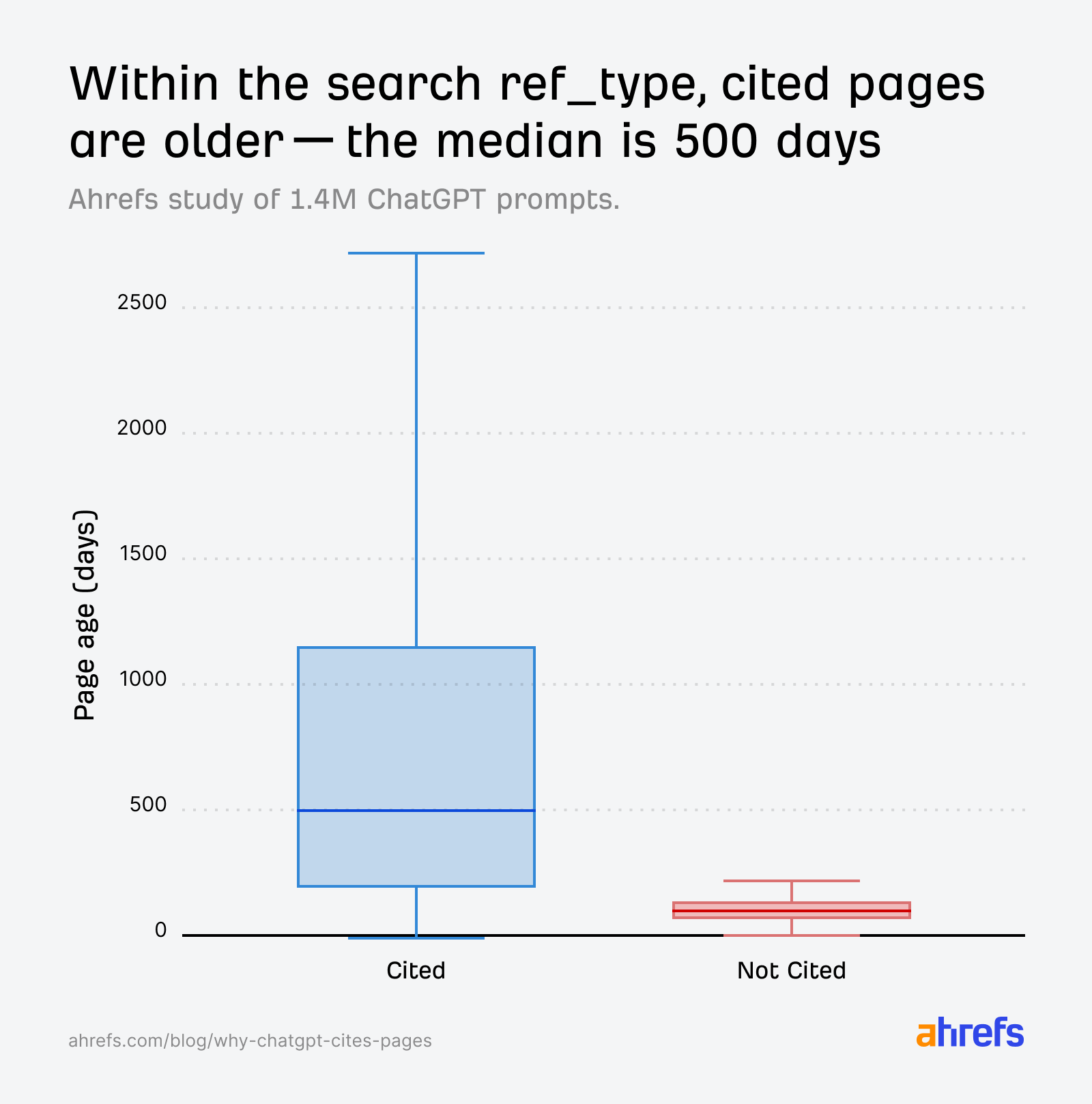
So within a single prompt’s retrieval set, it’s the older, more established pages that tend to get cited, and the freshest content that tends to get discarded.
In other words, ChatGPT prefers fresh content, but tends to cite comparatively “older” content more often. That sounds counterintuitive, but both things can be true at the same time.
Across the broader population of AI citations, ChatGPT does skew toward fresher when compared against Google results, and even against it’s own citation preferences only last year.
But within a given retrieval set, freshness alone isn’t enough. Relevance still does the heavy lifting.
A new page that matches fanout queries well will get cited. A new page that doesn’t will be retrieved, yet ignored.
It’s also worth pointing out that the pool of non-cited pages (~3M) across the search ref_type is far smaller than the cited group (~23M), which limits how confidently we can interpret the age gap.
Where freshness matters most is in “news”.
In this category, title relevance scores for cited and non-cited pages are nearly identical:
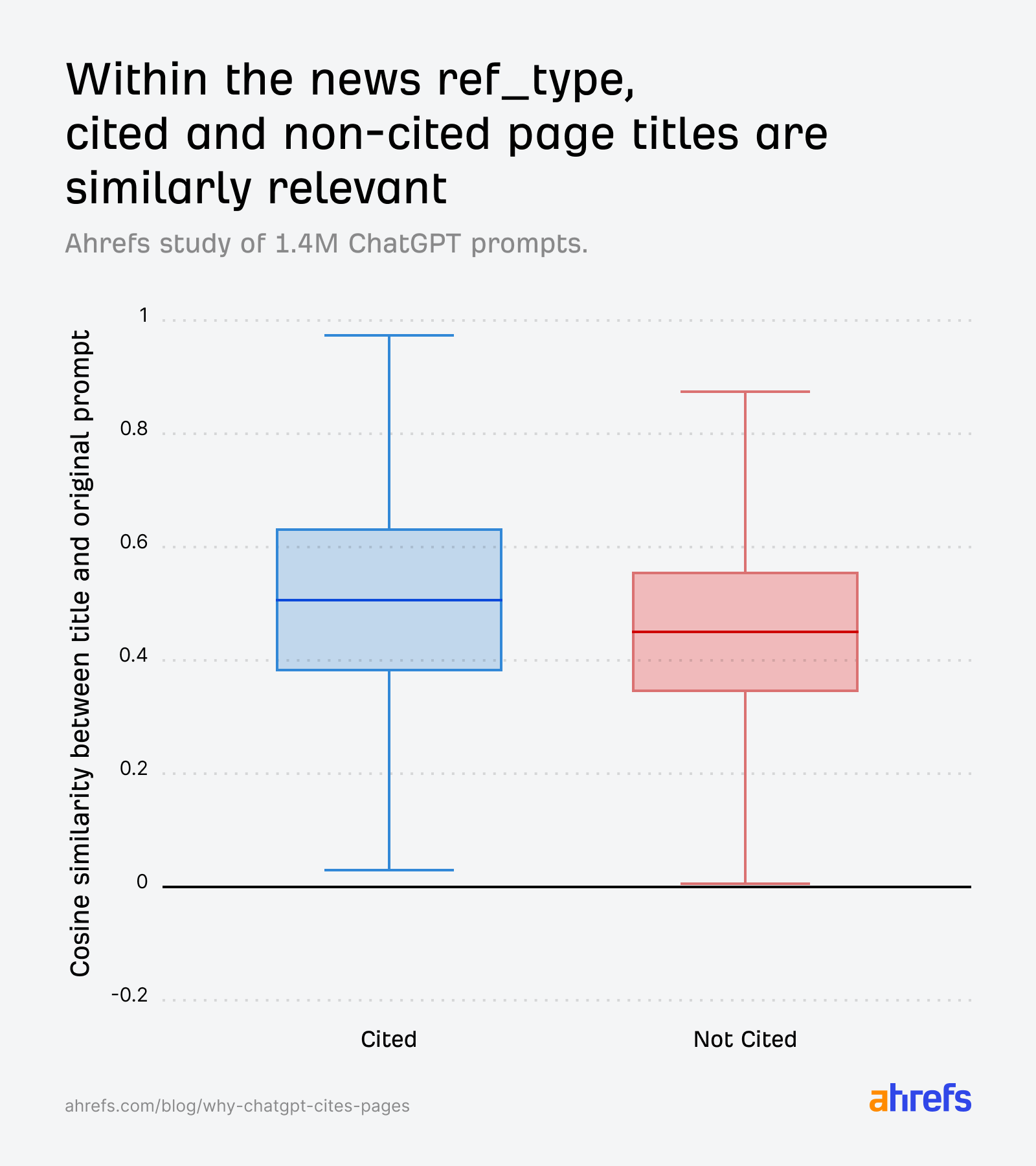
The AI can’t decide based on relevance alone, so it defaults to a temporal tie-breaker: page age. Cited news pages skew younger:
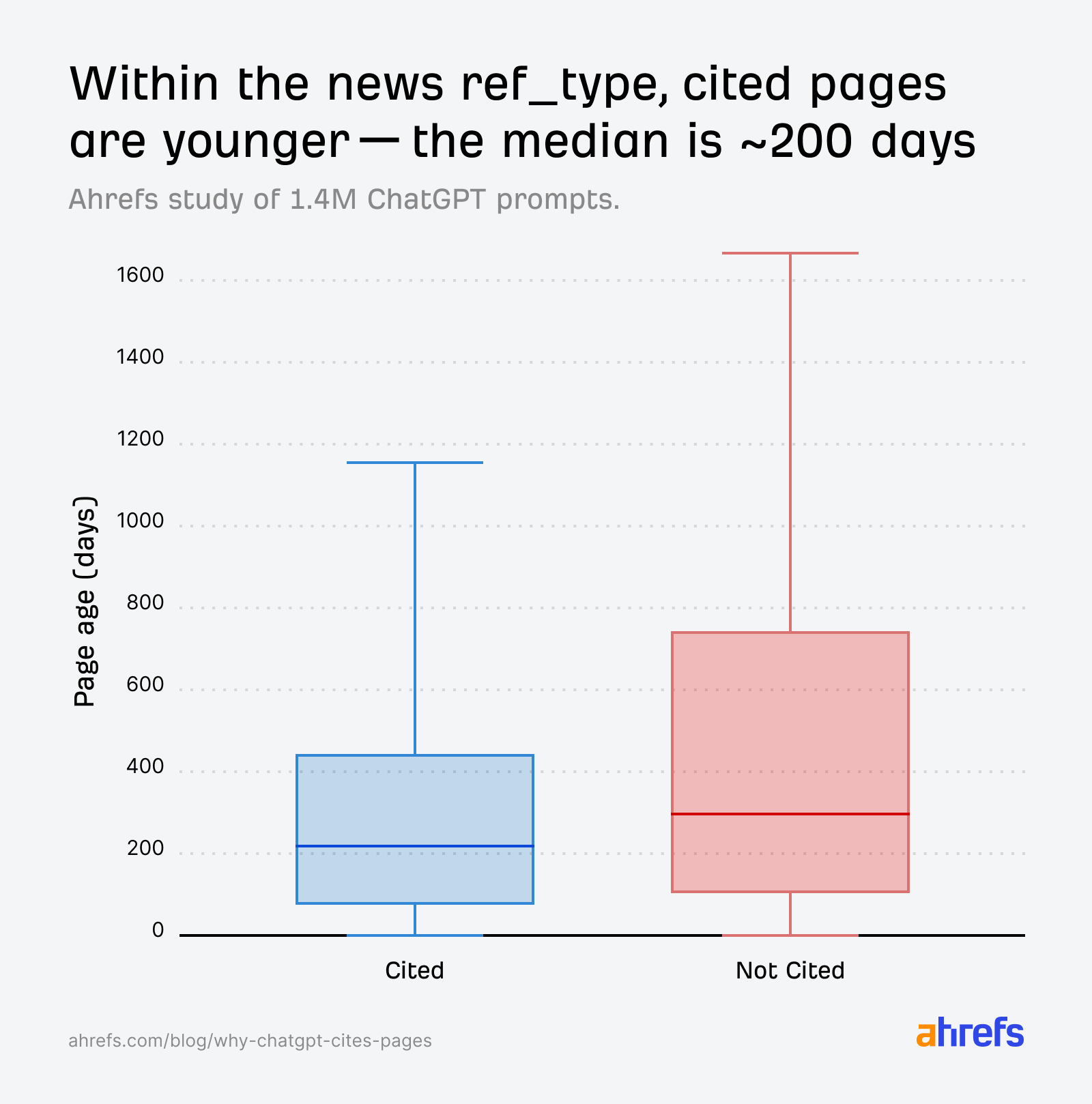
For news queries, younger pages have a clear advantage, even when relevance scores between cited and non-cited pages are similar.
Create the freshest news content using Firehose
If you publish news or time-sensitive content, freshness is non-negotiable.
Be the first to break news on certain stories using Ahrefs Firehose—our real-time web monitoring API that gives you a streaming feed of data from our huge crawler infrastructure.
For example, if you work in SaaS journalism, you can track content changes on pages like Google’s official blog, so you can be the first one to cover a new Google update as soon as it goes live.
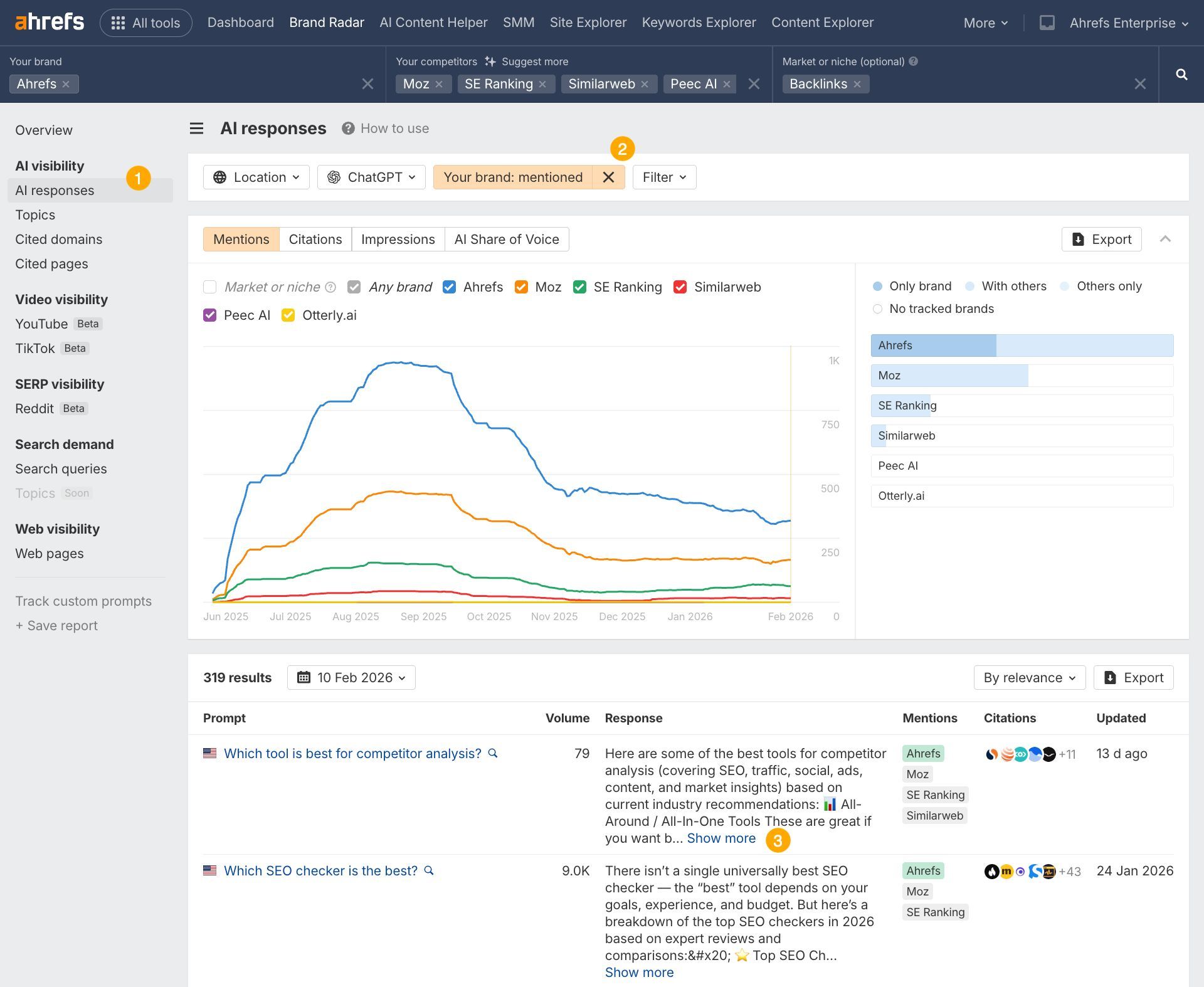
Then, use Brand Radar’s Mentions history in the AI Responses report to track whether your ChatGPT visibility spikes after publication.
The 1.4 million prompts paint a pretty clear picture. ChatGPT is an aggressive editor. It favors its general search index, uses semantic similarity to select and cite sources, and treats Reddit as a textbook it’s embarrassed to admit it read.
But the data also taught us a lesson in analytical caution.
Aggregate comparisons between “cited” and “non-cited” URLs can be misleading if the non-cited pool is dominated by a single source type with its own retrieval mechanics.
What initially looked like a paradox—less-optimized pages getting cited more—turned out to be a matter of dataset composition.
We would have got that one very wrong if we hadn’t isolated by ref_type.
Ultimately, the pages that get cited are the ones whose titles and content match the questions ChatGPT is asking behind the scenes, and that surface through the right retrieval channel.