Key Takeaways
- Most AI brand visibility tracking today replicates keyword tracking logic, using prompts instead of search terms. The underlying assumption is the same, and that’s the problem.
- Traditional search engines are deterministic: the same query tends to return similar results. LLMs are probabilistic: the same prompt can produce a wide range of valid answers.
- Measuring a probabilistic system with deterministic tools produces data that looks clean but doesn’t reflect how the system actually behaves.
- The prompts most brands are tracking (‘Best CRM in 2026,’ ‘Top accounting software’) describe a user who doesn’t exist, someone with no context, no history, and no specific intent. This is a known gap in current AI SEO measurement approaches.
- Fixing this requires a different measurement philosophy, not just better prompts.
Have you started tracking your brand in ChatGPT, Perplexity, or Google AI Overviews? Good. You’re thinking about the right problem.
Here’s the harder question: what are you actually measuring?
Most teams doing AI brand visibility tracking today have taken a familiar mental model and applied it to an unfamiliar system. Prompts have become the new keywords. Visibility scores have become the new rankings. Tracking platforms have emerged to show how often your brand appears in AI responses over time. On the surface, it looks like a natural evolution of the work you’ve already been doing.
It isn’t.
The tools built for traditional search were designed for a deterministic system, one where the same query reliably returns the same results. Large language models (LLMs) don’t work that way. They’re probabilistic: the same prompt can produce a range of valid answers, shaped by phrasing, context, model version, and more. Applying rank-tracking logic to a system that doesn’t produce ranks is the core mismatch, and it’s quietly corrupting the data most teams are reporting on.
This post breaks down exactly what’s going wrong and what a better approach looks like. It’s the first in a three-part series on AI visibility measurement. Part two introduces a structured framework for building prompts that actually reflect how your buyers use AI. Part three covers what the resulting data reveals about your content strategy.
The industry’s current approach to AI visibility measurement wasn’t irrational. It was fast. When a new channel emerges, teams reach for the tools and frameworks they already understand, and in digital marketing, that means rankings, share of voice, and tracked keywords. The logic was simple: prompts are the new search queries, so treat them the same way.
The problem is that search engines and LLMs are fundamentally different types of systems.
Traditional search is deterministic. Submit the same query to Google twice and you’ll get a broadly similar set of results. Position may shift slightly, but the system is stable enough that rank tracking works. That predictability is the entire foundation of AI keyword research and traditional SEO measurement.
LLMs are probabilistic. Run the same prompt multiple times and you’ll get a distribution of responses, not a fixed answer. The model generates each response based on statistical associations, not a retrievable index. There is no ‘rank one’ to hold.
The table below illustrates the mismatch. Applying rank-tracking logic to a probabilistic system doesn’t give you a less accurate version of the right answer. It gives you a fundamentally different kind of measurement entirely.
| Traditional Search | LLM Ecosystem | |
| System Type | Deterministic | Probabilistic |
| Behavior | Predictable / Stable | Variable / Generative |
| Core Metric | Rank (Position) | Presence (Likelihood) |
| Same query = same result? | Broadly yes | Not necessarily |
This isn’t a minor calibration issue. It’s structural. If you’re reporting on AI visibility using methods designed for predictable, stable systems, you’re building strategy on a foundation that doesn’t reflect how LLMs actually work.
The User Who Doesn’t Exist
The second flaw in current AI visibility tracking is less obvious but equally important.
Most prompt tracking today relies on generic, decontextualized inputs:
- ‘Best CRM in 2026’
- ‘Top accounting software’
- ‘Best project management tool for small teams’
These prompts are clean, scalable, and easy to standardize. They look exactly like the keywords we’ve always tracked.
They also don’t resemble how real people use AI tools.
Real users carry context. They have prior conversations, professional constraints, specific goals, and levels of knowledge that shape what they’re actually asking. A prompt like ‘Best CRM in 2026’ represents an abstract, anonymous user with no history, no constraints, and no intent beyond the words in the query.

So when you measure AI visibility using these prompts, you’re measuring how the model responds to a hypothetical person who rarely shows up in real decision-making moments. That’s directionally useful at best.
Real audit work bears this out. In one analysis, a brand showed strong visibility for broad category queries, the kind that show up well in standard tracking. But when prompts were shaped around the specific contexts their buyers actually operate in, visibility dropped to zero in the topics most directly connected to purchase decisions. The tracking looked healthy. The actual picture wasn’t.
Generic prompts measure AI visibility for a user who rarely exists. If you want to know how your brand appears to real buyers, you need inputs that reflect real buyer contexts.
The Scaling Trap
The instinctive response to ‘generic prompts aren’t representative’ is volume. If one prompt isn’t enough, run a thousand variations. Add synonyms, modifiers, intent signals, geographic qualifiers. Cover the space more thoroughly.
This logic leads directly into what we call the scaling trap.
Every topic branches into multiple phrasings, intents, personas, and contextual modifiers. The number of prompts required to meaningfully approximate reality grows exponentially. A topic with five main phrasings, three intent signals, and four persona types generates 60 prompt combinations before you’ve added geographic variation or industry context. Scale that across a full content strategy and you’re looking at tens of thousands of prompts, run repeatedly, across multiple models, on a recurring basis.

Two problems follow. The first is practical: the cost of running this at scale is significant, and it compounds across every client account and every reporting cycle. The second is more fundamental: even after all of that, there’s no guarantee the resulting dataset is meaningfully more representative of actual user behavior. You’ve scaled the volume without fixing the flaw in the input logic.
More prompts don’t fix a representativeness problem. They just make the flawed measurement more expensive.
What Good Measurement Actually Requires
If the problem is that prompts lack context, and brute-force volume doesn’t solve that, the answer is to improve the quality of the input rather than the quantity.
Good measurement of a probabilistic system requires asking a different question entirely. The old question was: ‘Where do we rank?’ The right question is: ‘How reliably does our brand appear when the conditions that actually matter are present?’
That shift has real implications. A brand that appears 85 percent of the time when the right persona and intent conditions are met has a genuinely strong position, even if its average visibility across generic prompts looks modest. A brand that appears 50 percent of the time on generic queries but near zero percent in high-intent, decision-stage contexts has a problem that average tracking completely obscures.
Visibility, measured correctly, is a probability distribution across specific user contexts, not a single score. Getting to that measurement requires inputs that reflect those contexts: structured prompts built around real user personas, specific intent stages, and the actual questions buyers ask when they’re close to a decision.
That’s the foundation of a better approach to AI visibility measurement. The next post in this series walks through exactly how to build it.

In the next post, I’ll walk through the framework we use at NP Digital to build prompts that reflect how real buyers actually engage with AI and what the data looks like when you do it right.
Why This Matters Now
AI-driven search has moved from a future consideration to a present reality, faster than most marketing teams anticipated.
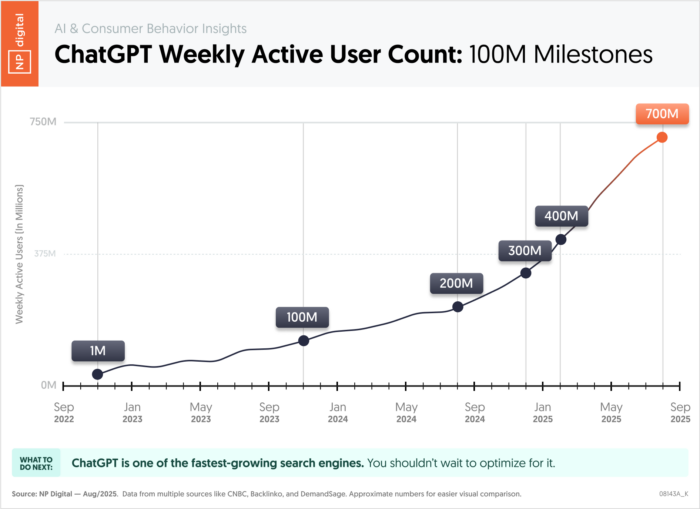
ChatGPT now has over 700 million users, with exponential growth going on. That’s not a niche research tool. That’s a primary discovery channel for a significant and growing share of your buyers.
Google AI Overviews now appear on roughly 48 percent of tracked queries, up 58 percent year over year according to BrightEdge data. In B2B technology, that figure reaches 82 percent of queries. If your buyers research software, services, or professional categories, AI is already shaping what they find before they ever reach your site.
The competitive dynamics are shifting accordingly. Brands that appear consistently in AI responses for the right queries, at the right intent stages, are building an advantage that compounds over time. Brands that don’t appear, or that appear for the wrong queries, are losing ground in the consideration phase before a sales conversation ever starts.
Every week you’re tracking AI visibility with flawed inputs is a week you’re making content and strategy decisions based on data that doesn’t reflect how your buyers actually use AI. The window to get ahead of this is open now.
FAQs
Why should I track AI brand visibility?
Your buyers are already using AI tools to research options, compare solutions, and form opinions about your category. Tracking AI brand visibility tells you whether your brand is present in those moments or invisible. Unlike traditional search, where a low ranking is visible and actionable, AI invisibility is silent, so you won’t know it’s happening unless you measure it.
What Is AI visibility?
AI visibility refers to how often and how favorably your brand appears in responses generated by AI tools like ChatGPT, Perplexity, Google Gemini, and Google AI Overviews. Strong AI visibility means your brand is being surfaced when users ask questions relevant to your product or service.
What are the top AI visibility solutions?
The most widely used platforms for tracking visibility include Writesonic and Profound, alongside a growing number of specialist tools. Each uses a defined prompt set to measure how often your brand appears across major AI platforms. The quality of your prompt set determines the quality of what you can learn — which is exactly the problem I want to address with this series.
Conclusion
Marketers aren’t doing something foolish by tracking AI visibility. They’re doing something natural: applying the tools and mental models they already know to a new channel. The problem is that those tools were built for a deterministic world, and LLMs don’t operate that way.
The mismatch matters. It means the data most teams are reporting on is structurally limited, not wrong exactly, but not representative of what’s actually happening when your buyers use AI to research your category.
The fix starts with a different question. Stop asking where you rank. Start asking how reliably you appear when it actually matters.
In the next post in this series, I walk through a framework built specifically for that question. This is a structured approach to prompt construction that reflects real buyer contexts and makes probabilistic measurement genuinely useful.
Are You Using Google Ads? Try Our FREE Ads Grader!
Stop wasting money and unlock the hidden potential of your advertising.
- Discover the power of intentional advertising.
- Reach your ideal target audience.
- Maximize ad spend efficiency.