

At Ahrefs, we publish many data-driven posts.
Publishing them is fun. Easy. And they get a ton of search traffic too.
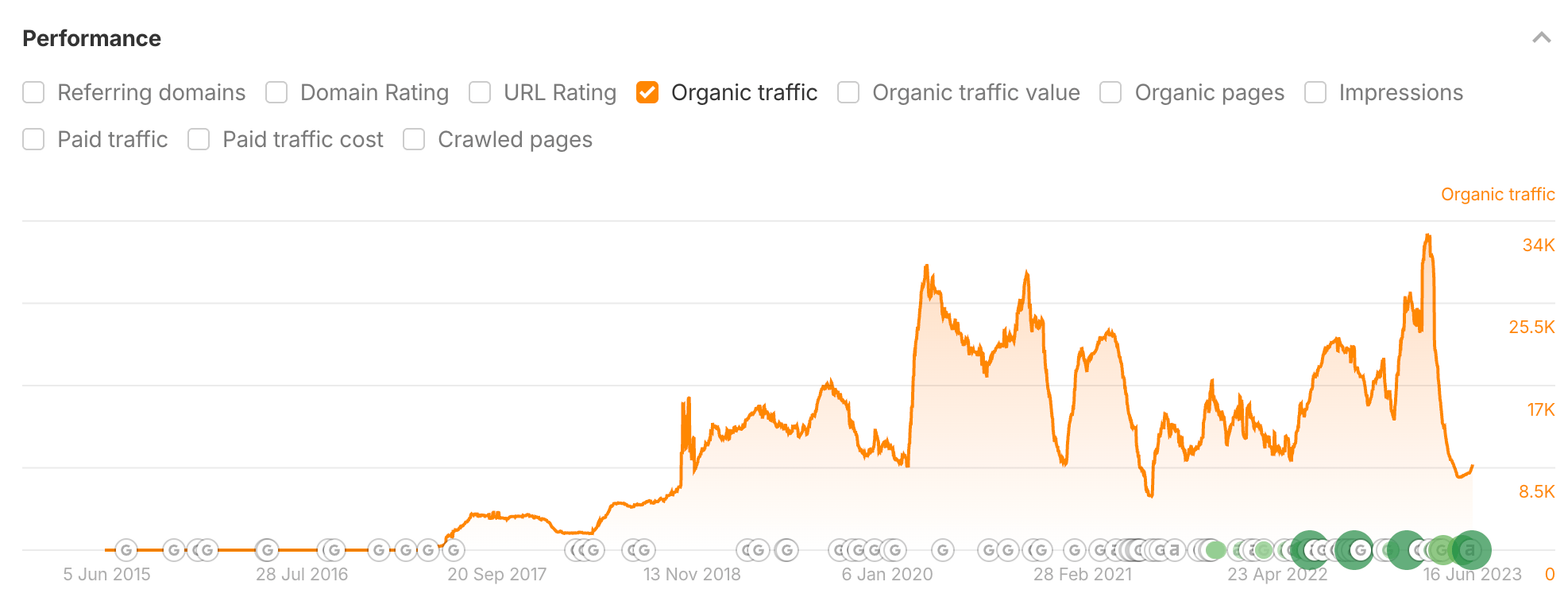
But such posts, like “Top Google Searches” or “Most Asked Questions on Google”, are only worth reading if the numbers are current.
Google knows that too, which explains the spike in search traffic every time we update the posts.
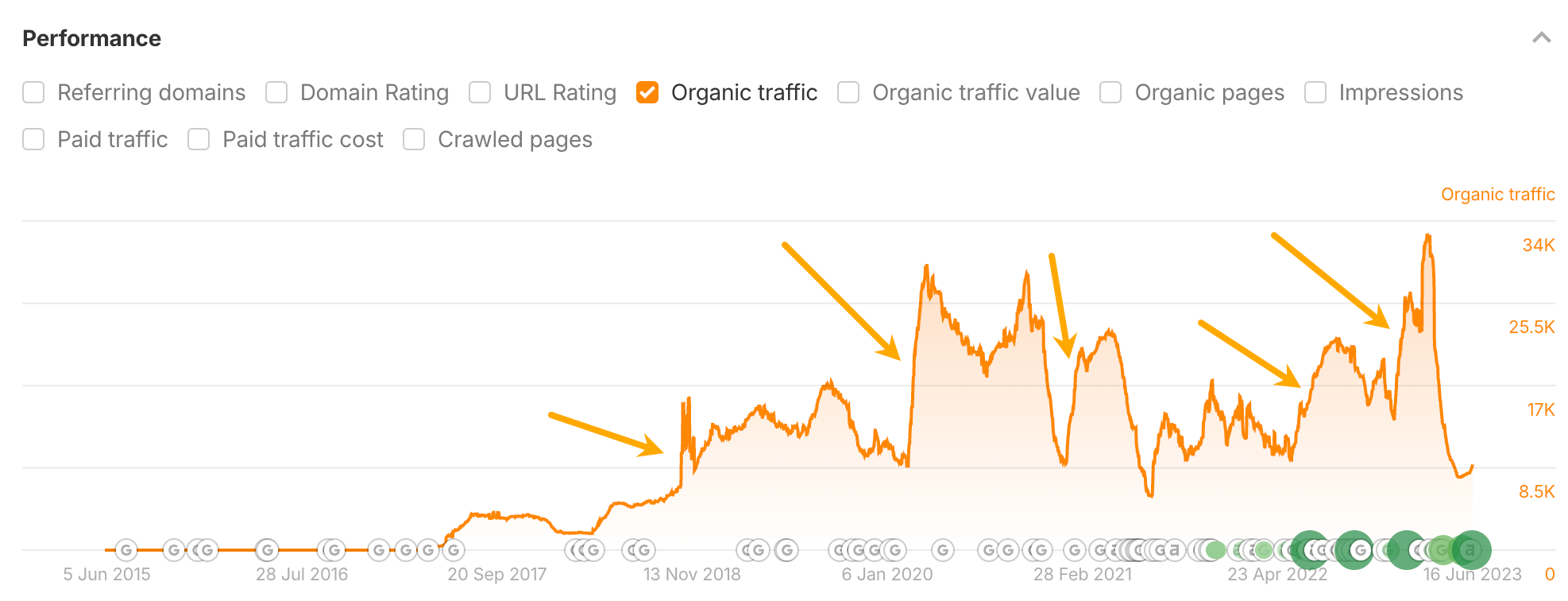
So someone has to keep them fresh.
Ideally, every month, someone (usually the author) had to pull fresh data from Ahrefs (or the API), clear out the junk and format the tables. The posts with custom charts were worse: spec the new chart, hand it to design, wait, review it, send it back for tweaks. Only then paste everything into WordPress without breaking the layout, update the dates, and republish.
One post is fine. Bearable tedium. But 14 posts? 20? The more you publish, the more it becomes a slog. I could lose a whole afternoon and have nothing to show for it except a post that said the same thing as last month with slightly different numbers.
It’s one of the most tedious jobs on the content team.
So, we made a compromise. We refreshed them every quarter. (And to be honest, there are some posts we never even got to.)
Fast forward to today. We don’t do that anymore. Letaido does it for us. It’s been running quietly for two months now. Altogether, it’s saving us at least 20 hours per month. Not only can we now update them every month, we can publish more of such posts, and update them regularly too.
It’s a genuine win/win: far less drudgery for us, and fresher, more accurate numbers for the reader.
Drop me some of that fire emoji, yes please.
Automating content marketing like this is apparently unfashionable to admit in 2026, with Gartner saying more than 40% of agentic AI projects will be scrapped by the end of 2027.

With the amount of LinkedIn bragging and much of “AI agent” demos being merely performative, I can understand the disillusionment. Fortunately, this one works.
But it works precisely because it’s boring. It doesn’t write our articles. It simply does the tedious part, which is a big part of content marketing.
I call it the Data Refresh Hub. It’s a tool that lives in our Letaido workspace.
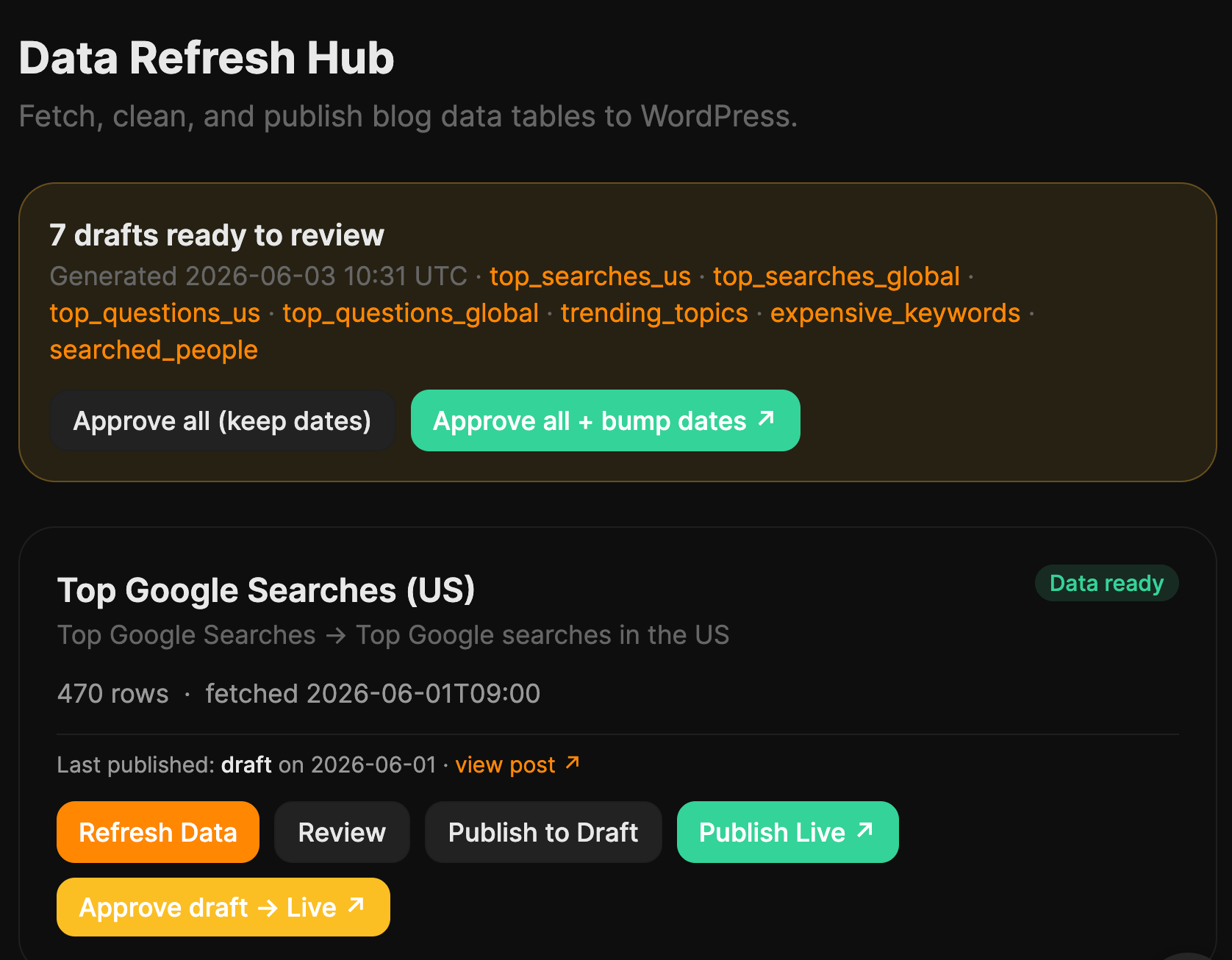
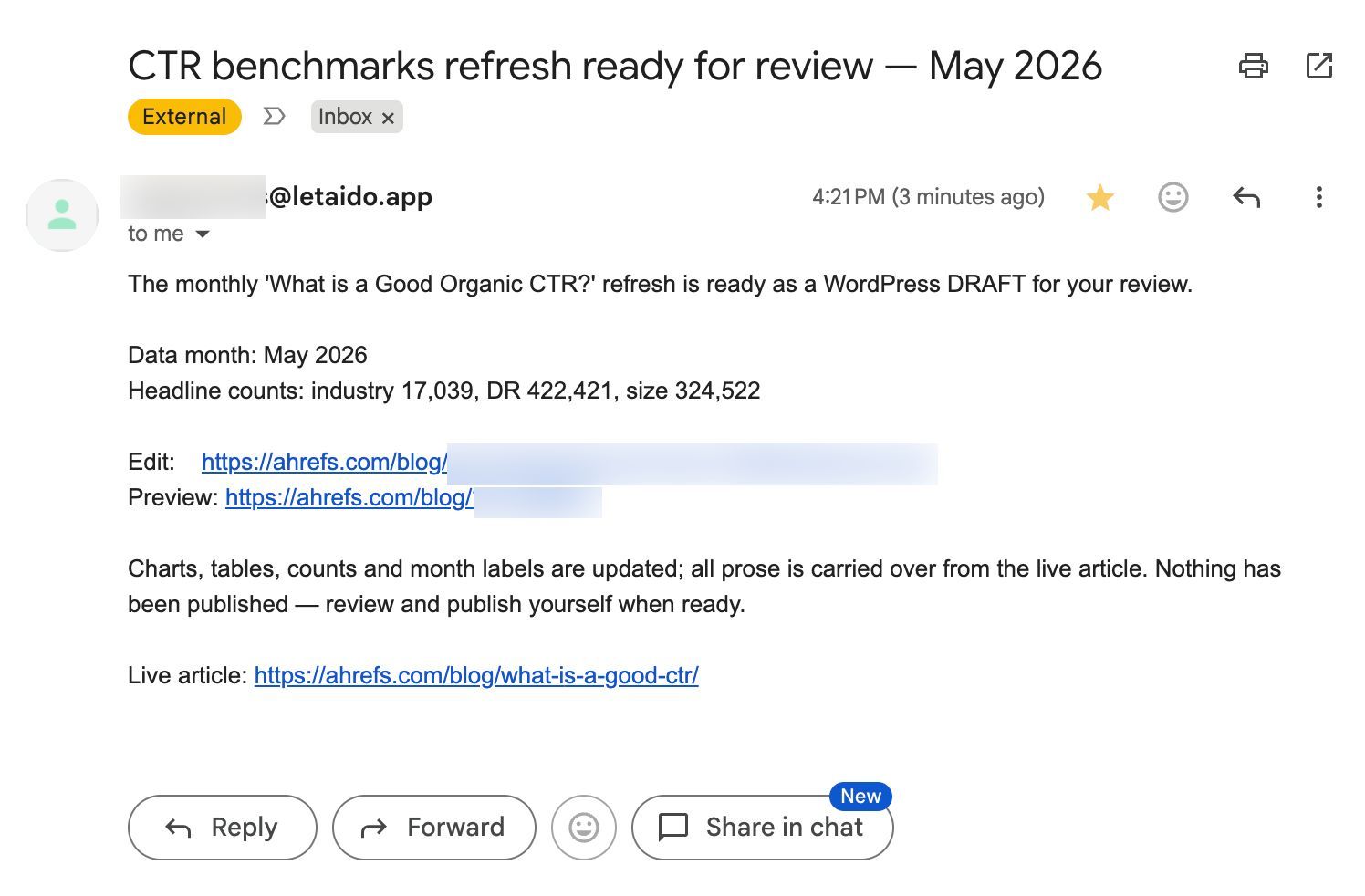
Once a month it pulls fresh data for all 14 datasets — keyword volumes and questions from Keywords Explorer, AI citations from Brand Radar — cleans each one by its own rules, and saves the results so I can see exactly what it kept and what it threw out. Then it builds a WordPress draft with the new tables in place and emails me to say it’s ready.

I want to be honest about how unglamorous the building was.
Getting the data alone meant three completely separate paths. I could get the US keyword tables easily via Letaido as it has all Ahrefs data. But the global ones weren’t available as it was custom-made by our data scientists previously for these posts. So I had to connect it to a separate internal service. Then I had to grab the AI citation tables from Brand Radar, one platform at a time.
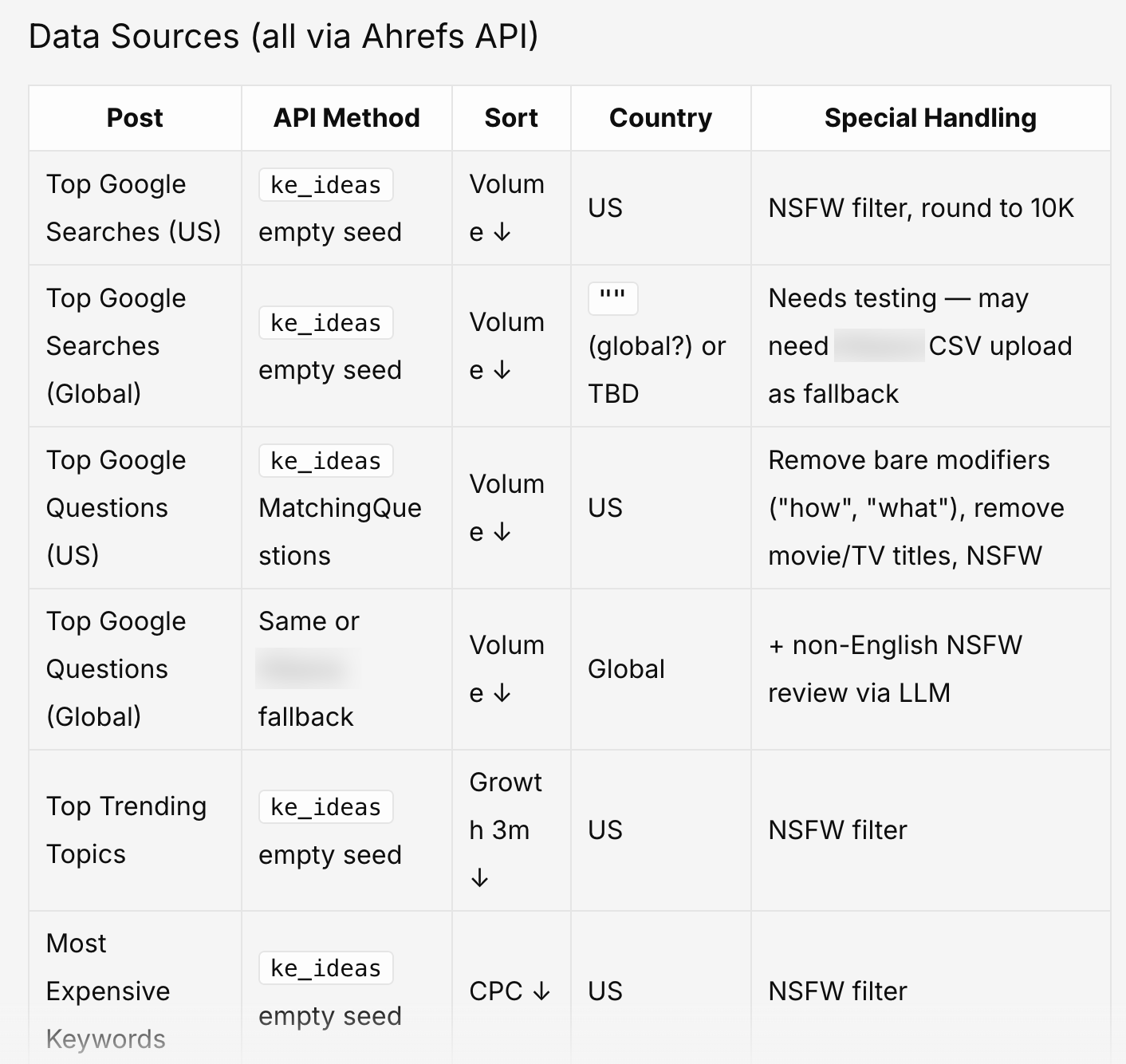
And then there are what seem to be silly problems. One build kept throwing a 500 error over a tiny capitalization mismatch: our code sent the field as Cpc, and the API insisted on CPC, all caps. I lost a genuinely embarrassing amount of time to that one.

Despite all of these, I want to say it was genuinely magic. After all, I didn’t hand-code any of this. I built it conversationally in Letaido. Letaido did all the work. Even the “time lost” was Letaido figuring out how to fix it, not me.
There are two jobs I kept deliberately human.
The first was judging what the agent produces.
Take “most asked questions on Google”. You’d assume pulling the top questions is just sorting by search volume. It isn’t. The raw list is full of things that look like questions but aren’t. “How to train your dragon” is a movie. “Would you rather questions” isn’t a question at all. Brand and product searches sneak in. So do oddly specific queries that read like a bot wrote them.
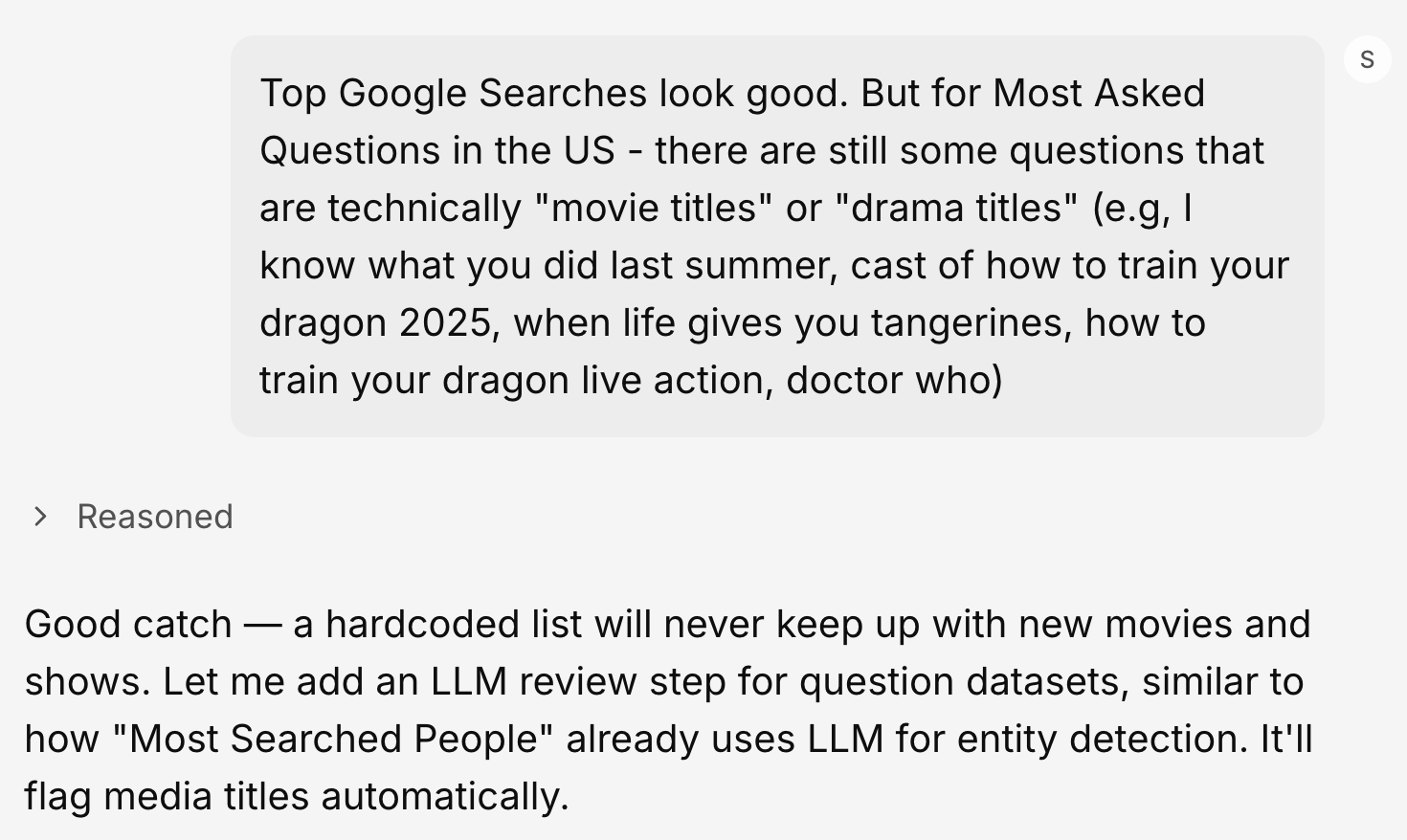
A person spots these in a second. So we run a cleaning layer, including an LLM pass, whose whole job is to make those calls at scale. For the “most searched people” table, it works through up to 5,000 candidates and decides what’s a real human name, what’s “[name] net worth”, and what’s just a normal word that happens to look like a name.
It’s good at this, but not perfect, which is exactly why I look at every refresh before it goes anywhere.
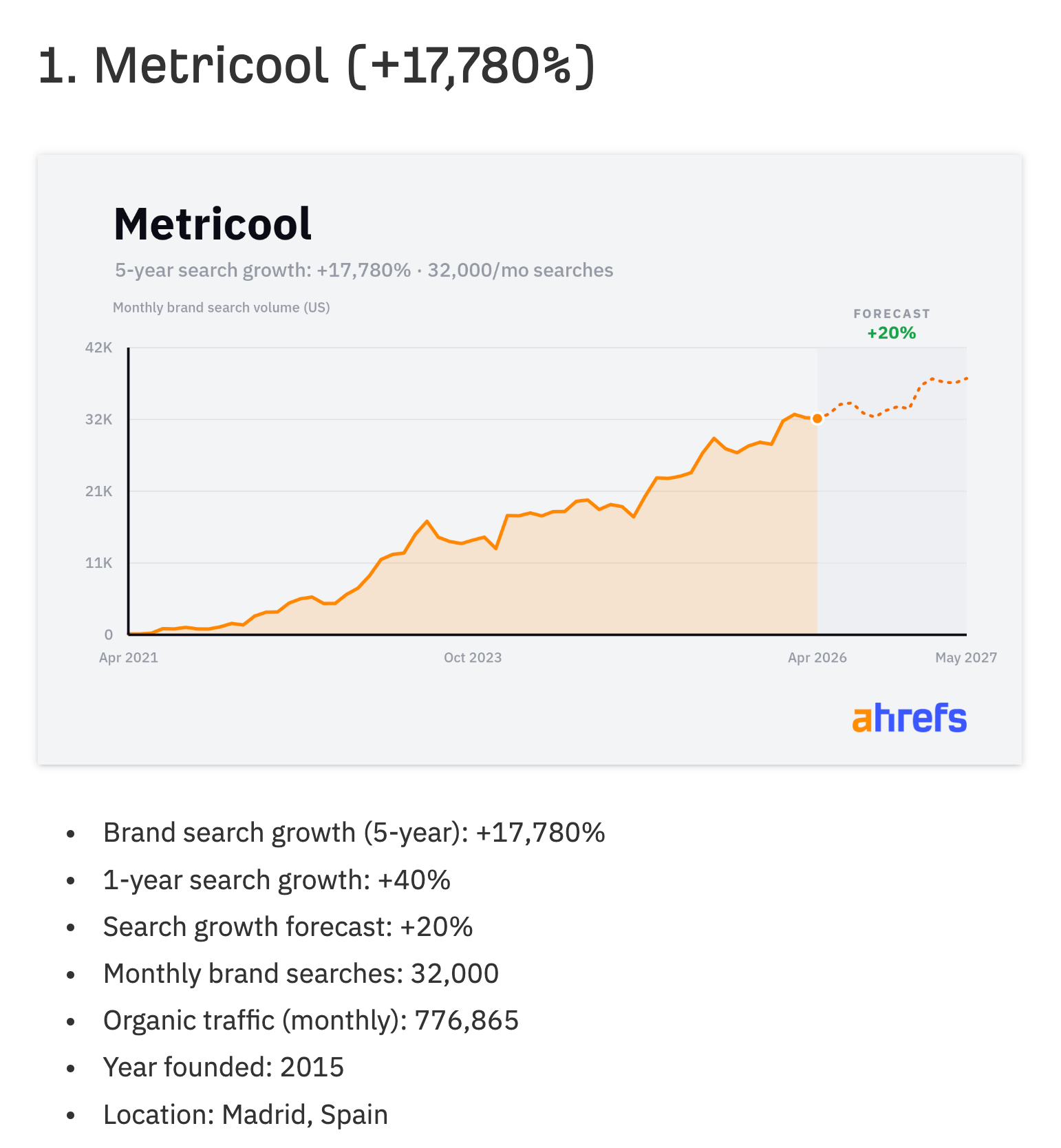
My colleague Louise ran into a harder version of the same problem. She built an agent that ranks the fastest-growing companies using Ahrefs data, and the deceptively hard part was teaching it what counts as a real breakout brand and what’s just noise.
Some company names are also ordinary words. You can’t measure the growth of “cursor” or “perplexity” from zero, because people were searching those long before the companies existed. So the system estimates how many searches the word was already getting before the brand emerged, subtracts that baseline, and counts only the brand-driven volume on top. The company stays on the list; only the pre-existing noise comes off.
Then it has to ignore one-month spikes that never hold, and actually Google each name to confirm the company itself ranks for it. Otherwise “Tropic” the software vanishes under Tropic the skincare brand. Every one of those rules is a call Louise made about what “real” means. The agent just enforces it.
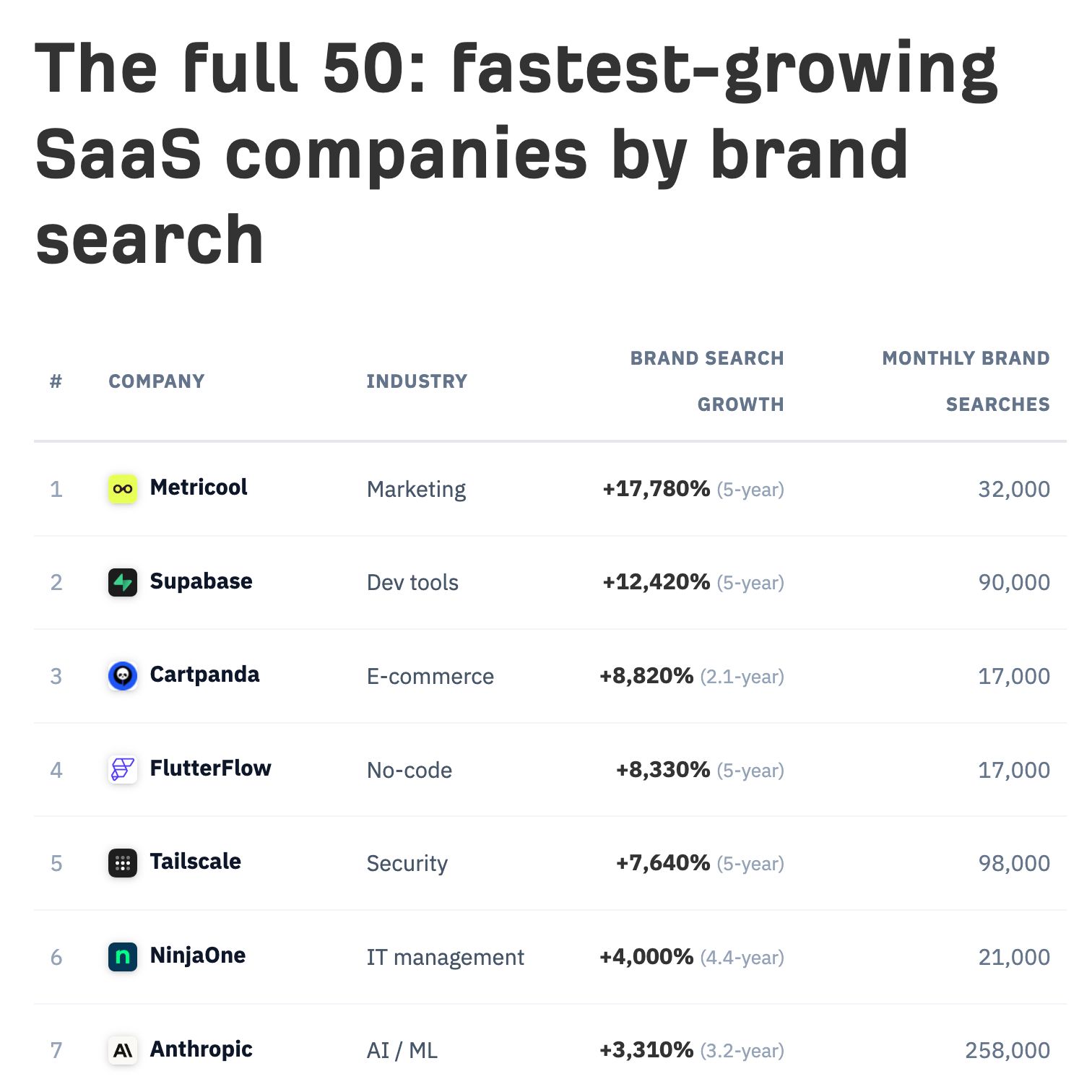
All human by the way.
This is also why the agent never publishes on its own. It creates a draft, and only goes live after a human confirms it.
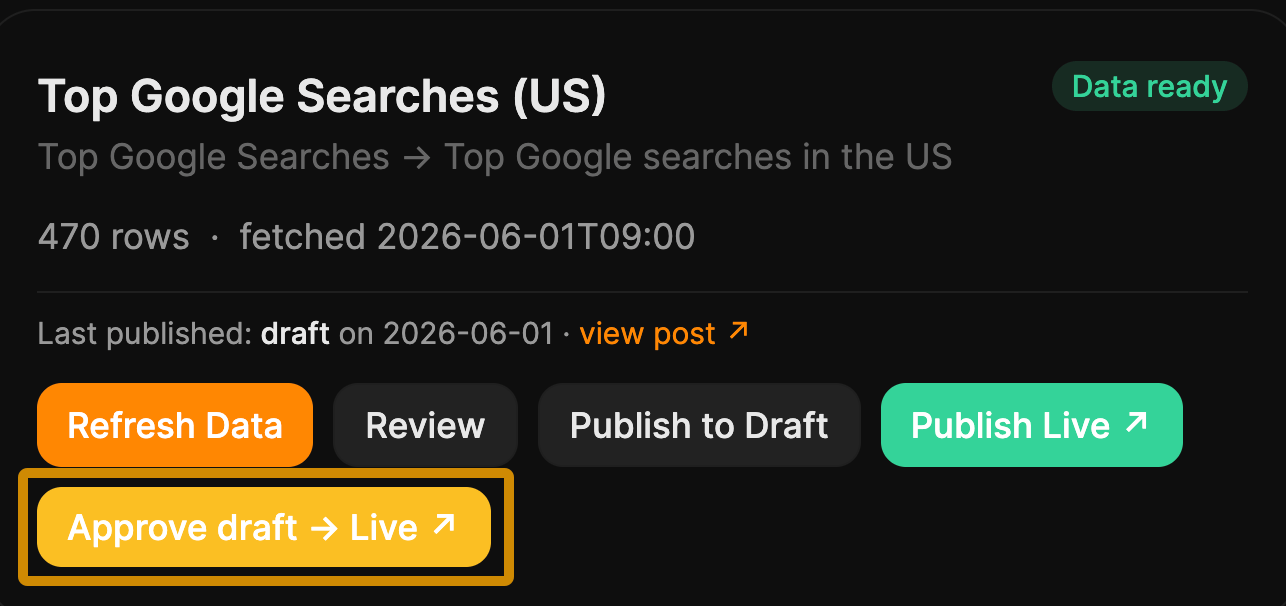
None of this sounds particularly impressive. But I think that’s the actual beauty of automation. I’m completely fine with an agent that does 90% of a job and leaves me the last 10%. An agent that does 100% and occasionally publishes nonsense to a live, public blog won’t be a time-saver. It’s asking for a fire to put out.
That’s why I still check it’s right and hit publish myself.
I originally built the Data Refresh Hub for my own posts. I didn’t think it was anything special, but I decided to share about it on Slack.
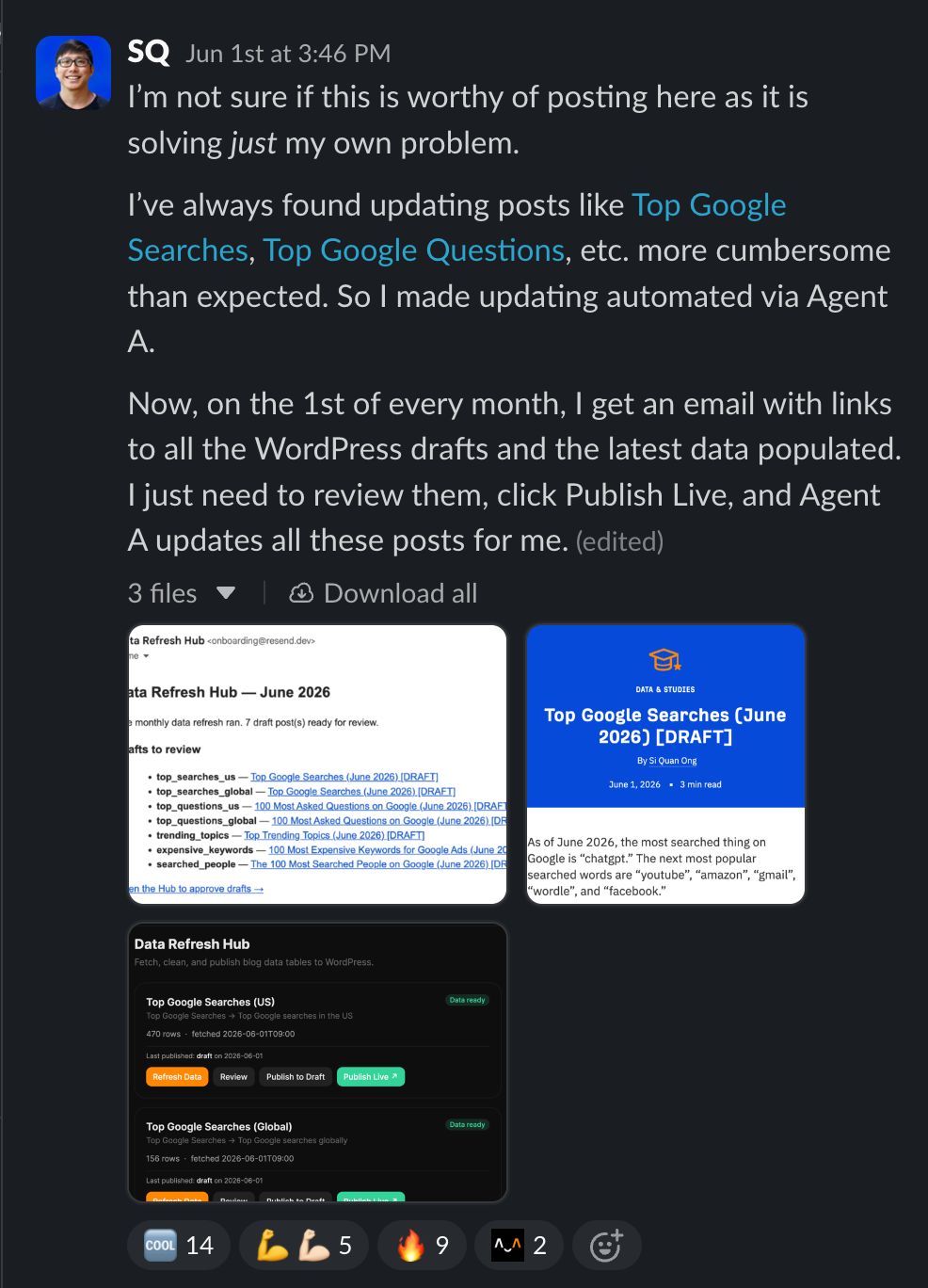
Turns out I actually underestimated what I did. It inspired my colleagues to start doing similar things.
Louise built a whole family of fastest-growing company rankings. She didn’t just update the data; she also used Letaido to add judgment, charts, and all sorts of other data.
Our Director of Content Marketing, Ryan, also set up the same kind of monthly automation for his own data content. His reaction, near enough word for word: “This was my dream for AI: actual automation, genuinely saving us hours of drudgery. And it is finally here. SORCERY!!!”

His version now runs on a schedule: pulls fresh data, regenerates the charts and tables, builds the WordPress drafts, makes the small date and sample-size edits, and emails him when the article’s ready to look at.
Nobody was told to do any of this. It spread because it worked, and the fact that it spread on its own (without anyone assigned to make it happen), is a clear sign that it’s real and not just a demo. Useful things just get copied, without anyone needing to call a meeting.
There are three of us running a version of this now.
I can almost guarantee that you have a job like this hiding in your own work. Most content teams do.
Here’s how I’d go looking for it.
Start with a question. Go through the work you do on repeat and ask two things of each task: does it run on a schedule, and could you write down the rules for what “done right” looks like?
If both answers are yes, it’s a candidate. “Pull the same numbers from the same place every month and reformat them the same way” passes easily. “Write the article” fails the second test, and that’s the part you might want to keep doing yourself anyway.
If what you’re running is marketing work, just go to Letaido and tell it what you need. It’ll do most of the hard, tedious work for you. (If you’re an Ahrefs customer, you get a free month.)
Then, if I had to boil down what actually made ours work:
- Automate the plumbing, not the thinking. Fetching, cleaning, formatting, pasting. These are all mechanical work and it’s exactly what you want to hand off. Keep the thinking part for yourself.
- Make the cleaning visible. Don’t let the agent just hand you a finished list. Get it to show you what it removed, and why, right next to what it kept.
- Keep a human at the gate. Drafts only. Let a person publish. This buys you most of the safety.
- Lock the things the model shouldn’t touch. Headline stats, verified figures, the opening line. You’d want to pin them down so the agent can’t quietly reword a number into something that isn’t true anymore.
That’s really all it is. It isn’t exciting, and sort of the point. The boring, well-defined jobs are the ones AI handles well today, and they’re sitting in plain sight in pretty much every content workflow.
This is one of the best parts of AI automation right now. It can help with all the work you quietly dread every single week or month.
Get an agent to do it, but be the editor that says it works and pushes live.
If there’s a lesson in here, it isn’t a very flashy one. Hand the boring, repetitive stuff to the machine, and keep the parts that actually need you.
We’re all managers now.